前にラズパイで構築したサーバーを使って来たけどHDD故障でデータが飛ぶのが怖くなってきた。。。
なのでもう一枚HDDを用意してRAID1を構築した。
今回はその手順について。
目次
はじめに
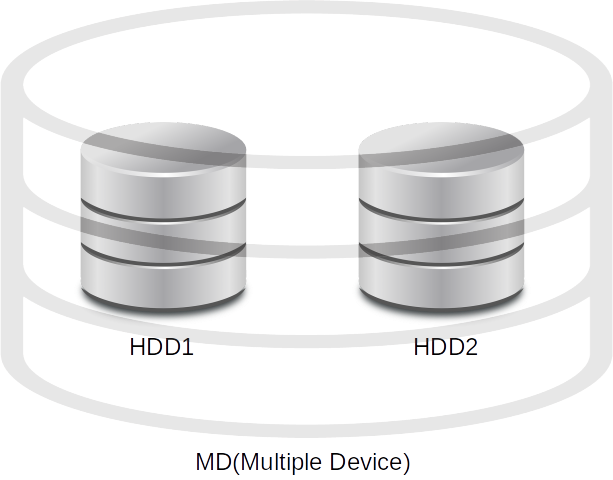
RAIDのイメージ
Linux上のRAIDのイメージは以下の図のようになる。
複数のHDDをまとめて1つのデバイス(Multiple Device)として扱う。
HDD確認
まずはRAIDに使いたいHDD確認(今回は実験のためUSBメモリ使用)。
以下で確認できる。
$ sudo fdisk -l ... Disk /dev/sda: 14.5 GiB, 15504900096 bytes, 30283008 sectors ... Disk /dev/sdb: 14.9 GiB, 15938355200 bytes, 31129600 sectors ...
今回はsdaとsdbのHDDでRAIDを構築する。
RAID用パーティション作成
新規パーティション作成
sdaとsdbのHDDにRAID用パーティションを作成する。
※このときHDDのデータは消去されるのでどこかにコピーしておく!
$ sudo fdisk /dev/sda Welcome to fdisk (util-linux 2.33.1). Changes will remain in memory only, until you decide to write them. Be careful before using the write command. Command (m for help): n Partition type p primary (0 primary, 0 extended, 4 free) e extended (container for logical partitions) Select (default p): p Partition number (1-4, default 1): First sector (2048-30283007, default 2048): Last sector, +/-sectors or +/-size{K,M,G,T,P} (2048-30283007, default 30283007): Created a new partition 1 of type 'Linux' and of size 14.4 GiB.
特にこだわりがなければデフォルトのままEnterを押していけば良い。
※パーティションが作成できないとき
以下のようにパーティション作成ができない場合は一回パーティションを消してから実行する。
$ sudo fdisk /dev/sda Welcome to fdisk (util-linux 2.33.1). Changes will remain in memory only, until you decide to write them. Be careful before using the write command. Command (m for help): n All space for primary partitions is in use. # パーティション作成できない Command (m for help): d # パーティション削除 Selected partition 1 Partition 1 has been deleted.
パーティションタイプの変更
パーティションタイプをRAID用のLinux raid autoに変更する。
$ sudo fdisk /dev/sda Welcome to fdisk (util-linux 2.33.1). Changes will remain in memory only, until you decide to write them. Be careful before using the write command. Command (m for help): t Selected partition 1 Hex code (type L to list all codes): fd Changed type of partition 'Linux' to 'Linux raid autodetect'.
HDDの変更を保存
下記で変更を保存する。
Command (m for help): w The partition table has been altered. Calling ioctl() to re-read partition table. Syncing disks.
一連の作業をsdbでも同様にして行う。
RAID設定
まずはRAID用パッケージmdadmをインストール。
$ sudo apt update $ sudo apt install mdadm
mdadmによりRAIDを構築する。
$ sudo mdadm --create /dev/md0 --raid-devices=2 --level=raid1 /dev/sda1 /dev/sdb1
- 基本構成:
mdadm [モード] <RAIDデバイス名> [オプション] <RAID構成デバイス> - --create: RAID作成モード
- /dev/md0: RAIDデバイス名を/dev/md0に
- --raid-devices=2: RAID構成デバイス数2
- --level=raid1: RAID種類をRAID1に
- /dev/sda1 /dev/sdb1: RAID構成デバイスを/dev/sda1, /dev/sdb1に
RAID構成デバイスの容量に差が1%以上あると以下の警告がでる。
特に問題がなければyで続行。
RAIDデバイスの容量は小さい方のデバイスの容量となる。
mdadm: largest drive (/dev/sdb1) exceeds size (15131264K) by more than 1% Continue creating array? y mdadm: Defaulting to version 1.2 metadata mdadm: array /dev/md0 started.
上記のコマンドを実行するとしばらくRAID構成の処理がバックグラウンドで実行される(結構時間かかる)。
進捗状況は以下で確認できる。
$ sudo watch cat /proc/mdstat Personalities : [raid1] md0 : active raid1 sdb1[1] sda1[0] 15131264 blocks super 1.2 [2/2] [UU] [===========>.........] resync = 58.8% (8901056/15131264) finish=12.0min speed=8620K/sec unused devices: <none>
$ sudo mkfs -t ext4 /dev/md0
RAIDデバイスの使用
構築したRAIDデバイスは通常のHDDと同様にマウントして使用することができる。
$ mkdir /home/user00/Share/md0 #マウント先ディレクトリ作成 $ sudo mount /dev/md0 /home/user00/Share/md0 #マウント
マウント後、rootでないと書き込みが出来なくなっていて煩わしかったら、chownで所有者を変更する。
$ sudo chown -R user00:user00 /home/user00/Share/md0
設定の保存
再起動後も使えるように設定を保存する。
設定情報は以下で取得できる。
$ sudo mdadm --detail --scan ARRAY /dev/md/0 metadata=1.2 name=raspberrypi:0 UUID=a6a07a86:3ea1907b:727d6c92:0bfc2e73
これを/etc/mdadm.confに書き込む。
$ sudo vim.tiny /etc/mdadm.conf ARRAY /dev/md0 metadata=1.2 name=raspberrypi:0 UUID=a6a07a86:3ea1907b:727d6c92:0bfc2e73 ~ ~ ~
さらに起動時にマウントするよう/etc/fstabにも以下を追記。
/dev/md0 /home/user00/Share/md0 ext4 defaults,nofail 0 0
有事の際
構成HDDの故障検知
RAIDなので構成HDDに異常があってもmd0上のデータはいつもどおりアクセスできる。
しかし、気づかないうちに残りのHDDが故障してしまったらせっかくRAIDにした意味がなくなるので知る必要がある。
構成HDDの異常は以下で調べることができる。
$ sudo cat /proc/mdstat
実際に一方のHDDを抜いて挙動を見てみる。
sdbのHDDを抜いてみた。
# 正常時の出力 Personalities : [raid1] md0 : active raid1 sdb1[1] sda1[0] 15131264 blocks super 1.2 [2/2] [UU] unused devices: <none> # 異常時の出力 Personalities : [raid1] md0 : active raid1 sda1[0] 15131264 blocks super 1.2 [2/1] [U_] unused devices: <none>
下記で更に詳細に調べることができる。
$ sudo mdadm --detail /dev/md0 /dev/md0: Version : 1.2 Creation Time : Sun Nov 29 17:41:25 2020 Raid Level : raid1 Array Size : 15131264 (14.43 GiB 15.49 GB) Used Dev Size : 15131264 (14.43 GiB 15.49 GB) Raid Devices : 2 Total Devices : 1 Persistence : Superblock is persistent Update Time : Sun Nov 29 19:33:34 2020 State : clean, degraded Active Devices : 1 Working Devices : 1 Failed Devices : 0 Spare Devices : 0 Consistency Policy : resync Name : raspberrypi:0 (local to host raspberrypi) UUID : a6a07a86:3ea1907b:727d6c92:0bfc2e73 Events : 28 Number Major Minor RaidDevice State 0 8 1 0 active sync /dev/sda1 - 0 0 1 removed
故障HDDの交換
故障したHDDを新しいのに交換する手順。
まず、故障したHDDをRAID構成から除外する。
$ sudo mdadm /dev/md0 --remove /dev/sdb1
次に新しいHDDを取り付け、RAID用パーティション作成(前述)を行う。
そして、新しいHDDをRAID構成に加える。
$ sudo mdadm --add /dev/md0 /dev/sdb1
はじめてRAIDを構成したときのように、しばらくRAID構成の処理がバックグラウンドで実行されるので待つ。
処理が完了したら交換完了。以下のように正常にRAIDが動いていることが確認できる。
$ sudo cat /proc/mdstat Personalities : [raid1] md0 : active raid1 sdb1[2] sda1[0] 15131264 blocks super 1.2 [2/2] [UU] unused devices: <none>
その他
RAIDの解除/再構築
RAIDの解除。
$ sudo umount /dev/md0
$ sudo mdadm --stop /dev/md0
mdadm: stopped /dev/md0
RAIDの再構築。
$ sudo mdadm --assemble /dev/md0 /dev/sda1 /dev/sdb1 mdadm: /dev/md0 has been started with 2 drives. $ sudo mount /dev/md0 /home/user00/Share/md0

























